Research
Research Interests:
1. Natural Language Processing - factuality and hallucination of large language models (LLMs), personalization of LLMs, investigating the multilingual and multimodal capabilities of LLMs.
2. Application of Natural Language Processing and Computer Vision in medicine (such as medical image analysis, autism detection, and psychological testing).
1. Natural Language Processing - factuality and hallucination of large language models (LLMs), personalization of LLMs, investigating the multilingual and multimodal capabilities of LLMs.
2. Application of Natural Language Processing and Computer Vision in medicine (such as medical image analysis, autism detection, and psychological testing).
Current Research
Impact of LLM Quantization on Text Quality
Conducting experiments to study the impact of quantization and speculative decoding on the quality of LLM-generated text, particularly factuality and hallucination. (Supervisor: Prof. Mohit Iyyer)
Cross-domain Personalization for LLMs
Creating a benchmark dataset for fine-tuning LLMs to generate personalized responses based on data from multiple sources such as Google Scholar, LinkedIn, Twitter, and home pages. (Supervisor: Prof. Hamed Zamani)
Projects at UMass Amherst
CS4: Measuring the Creativity of Large Language Models Automatically by Controlling the Number of Story-Writing Constraints
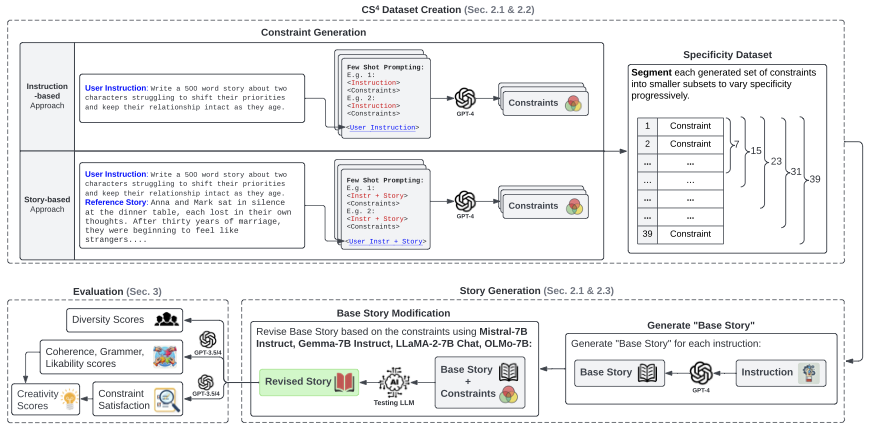
Evaluating the creativity of large language models (LLMs) in story writing is difficult because LLM-generated stories could seemingly look creative but be very similar to some existing stories in their huge and proprietary training corpus. To overcome this challenge, we introduce a novel benchmark dataset, \datasetnospace, with varying levels of prompt specificity. By increasing the number of requirements/constraints in the prompt, we can increase the prompt specificity and hinder LLMs from retelling high-quality narratives in their training data. Consequently, CS4 empowers us to indirectly measure the LLMs' creativity without human annotations.
Our experiments on LLaMA, Gemma, and Mistral not only highlight the creativity challenges LLMs face when dealing with highly specific prompts but also reveal that different LLMs perform very differently under different numbers of constraints and achieve different balances between the model's instruction-following ability and narrative coherence.
Additionally, our experiments on OLMo suggest that while reinforcement learning with human feedback (RLHF) enhances LLMs' ability to output superior narratives under limited constraints, its effectiveness diminishes severely in the presence of more constraints. The results suggest that RLHF can help LLMs select better stories from their training data but has limited influence in boosting LLMs' ability to produce creative stories that are unseen in the training corpora. (GitHub, Paper)
Fine-Tuning Intelligence: Exploring Dynamic Prompts in RLHF for Improved Alignment
The alignment problem, ensuring AI systems adhere to human values, remains a significant challenge despite the collection of increasingly high-quality and expensive datasets. Reinforcement Learning from Human Feedback (RLHF) offers a promising solution, leveraging human judgment during training. However, standard RLHF often relies on static prompts, potentially wasting resources and neglecting areas needing improvement. This work proposes a novel approach for efficient and effective RLHF fine-tuning of large language models (LLMs). We introduce a dynamic prompt generation system that adapts based on the model’s intermediate performance. This allows the model to focus on areas requiring the most human guidance, leading to faster and more targeted alignment. We evaluate our method by comparing three models trained with the same resources: a standard RLHF baseline, a Starts-On-Policy (SOP) model with static prompts based on initial performance, and our Always-On-Policy (AOP) model with dynamically generated prompts. Results demonstrate that AOP significantly outperforms all other models showcasing the effectiveness of our approach.
Projects at the University of New England, Australia
Understanding non-verbal Vocalizations from Minimally-verbal Autistic Individuals: A Transfer Learning Approach
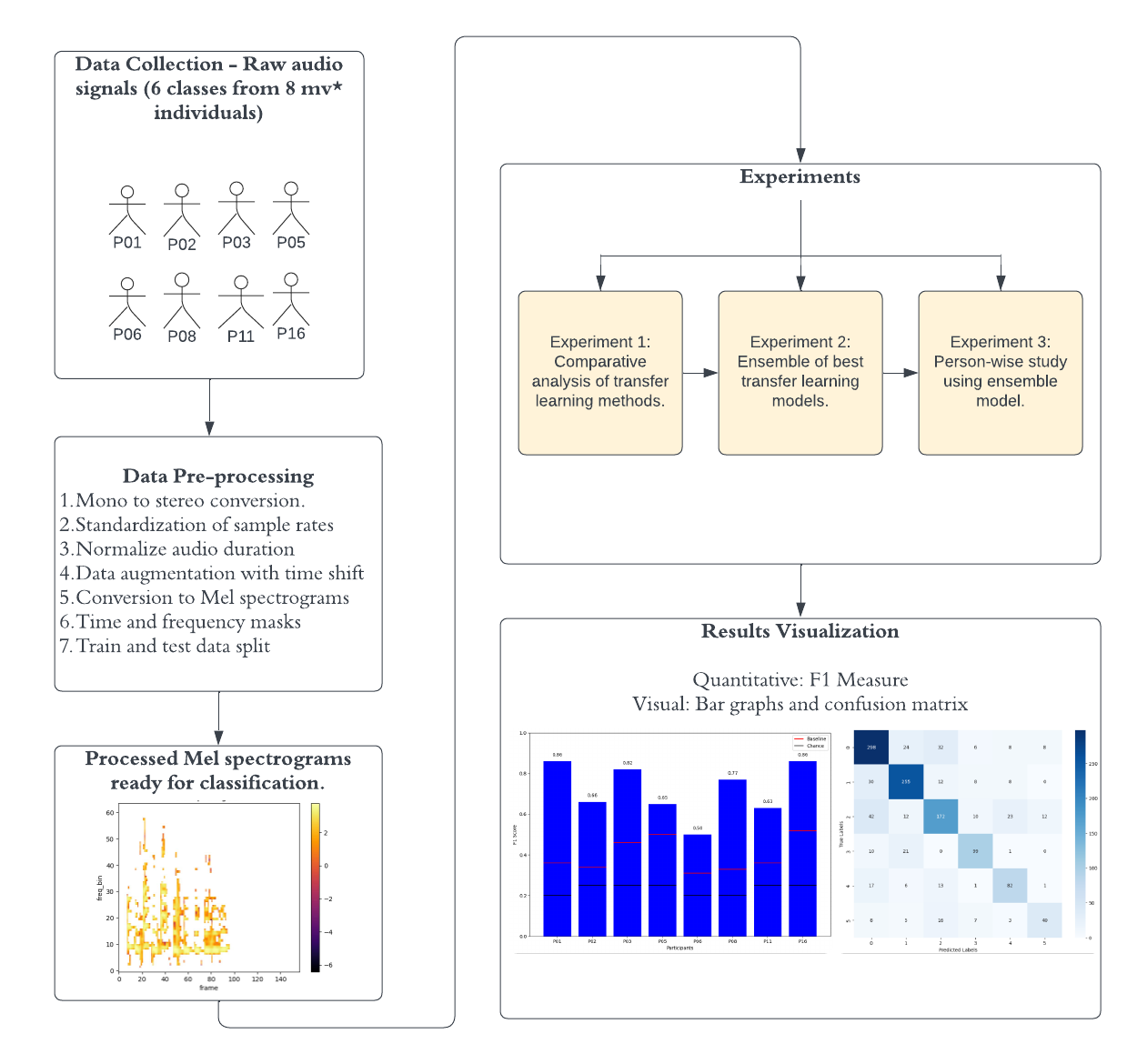
Autism Spectrum Disorder (ASD) often includes challenges in verbal communication, particularly for minimally verbal (mv*) individuals. Mv* individuals with ASD often find it difficult to communicate with people since their vocalizations are highly personalized and often non-verbal, making it extremely difficult for people to understand their needs. Recent advances in machine learning and deep learning have made it possible for researchers to explore new avenues and provide personalized care for individuals with ASD. This research explores transfer learning and Mel spectrograms to classify non-verbal vocalizations from mv* ASD individuals, aiming to improve understanding and communication. We conduct three experiments to verify the robustness and generalizability of our approach in different setups. Using a dataset of 7077 vocalizations from eight mv* individuals collected from noisy, real-world settings, we convert the audio signals to Mel spectrograms and evaluate six transfer learning models and a custom convolutional neural network model. Our experiments demonstrated that DenseNet161, ResNet101, and VGG19, particularly when combined in an ensemble, effectively classify vocalizations into six categories: self-talk, frustration, delight, dysregulation, social, and request. Results suggest that this ensemble achieves state-of-the-art performance with an F1 score of 0.79, outperforming traditional machine learning methods and highlighting the potential of artificial intelligence in enhancing care for mv* ASD individuals. (GitHub)
Do Deep Learning Models Mimic Human Personality Traits? – An Empirical Study
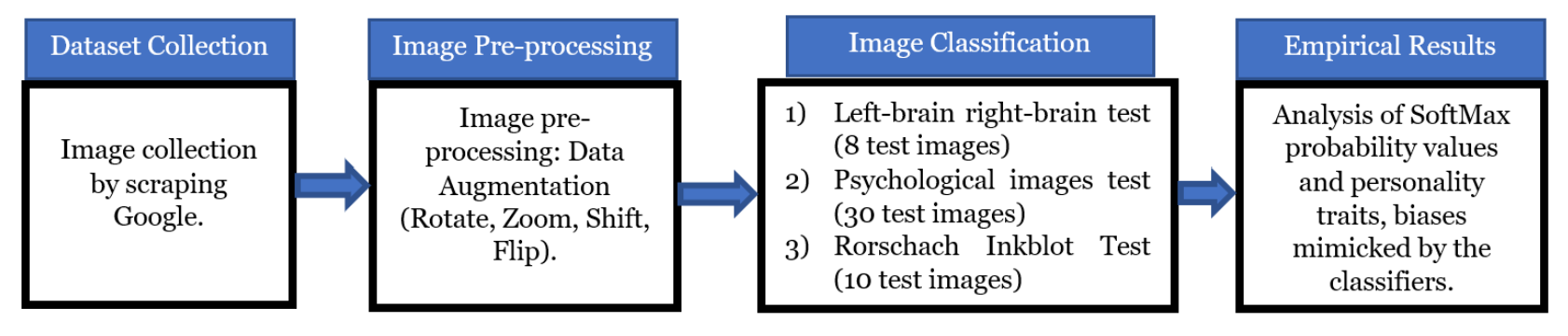
Two key aspects of artificial intelligence are its ability to make decisions and attempt to mimic humans. Decision-making in humans is, however, not straightforward and depends significantly on the person’s mental state, personal biases, and personality. In this study, we attempt to empirically understand if deep learning image classifiers also exhibit such inherent biases or if they act neutrally in any given situation. To this end, we perform three experiments – left-brain right-brain test, psychological images test, and Rorschach’s inkblot test on eight different state-of-the-art deep learning classifiers. A detailed analysis of the SoftMax probability scores is done rather than an analysis on measures like accuracy and F1. The experimental results suggested that most models work similar to a left-brained person, do not always predict the same class when given images consisting of multiple object classes, and usually detect larger objects rather than smaller ones. We believe that understanding these inherent biases would help future researchers take necessary actions while building image classification models. (GitHub, Paper)
Hidden and Face-like Object Detection Using Deep Learning Techniques – An Empirical Study
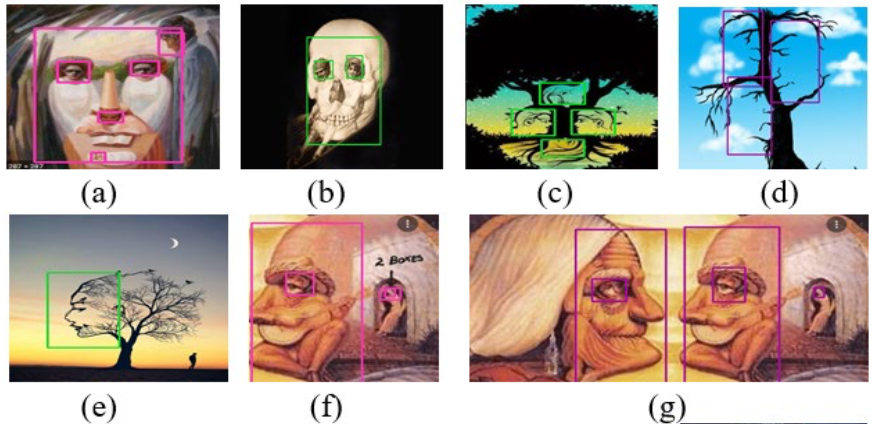
An essential aspect of artificial intelligence is how closely machines can mimic humans. One of the motivations for developing intelligent systems is human vision. While trying to recognize a class of images, it is as vital to distinguish the class of images from similar-looking objects and identify them in hidden places as it is to create bounding boxes and learn to localize the position of the object. Traditionally, deep learning models have performed exceptionally well in image classification and object detection tasks. In this work, we perform four experiments to train machines to distinguish between real faces and face-like objects and to recognize them. Nine state-of-the-art deep learning-based classifiers have been chosen to perform a comparative study on the designed experiments. Using these experiments, we establish that training models on real faces does not prepare them to identify face-like objects, and at the same time, training on face-like objects enables the models to detect face-like images even while hidden amongst other images. Despite work being done in the fields of camouflage detection and optical illusion detection, to the best of our knowledge, no work has been done in training and testing machines to distinguish between face and face-like objects with deep learning methods. This work could help researchers make better camouflage detection systems, perform context-sensitive studies, understand the biases that various models possess towards certain classes of images, and have applications in real life such as military and self-driving cars. (GitHub, Paper)
Artificial intelligence-based suicide prevention and prediction: A systematic review (2019–2023)
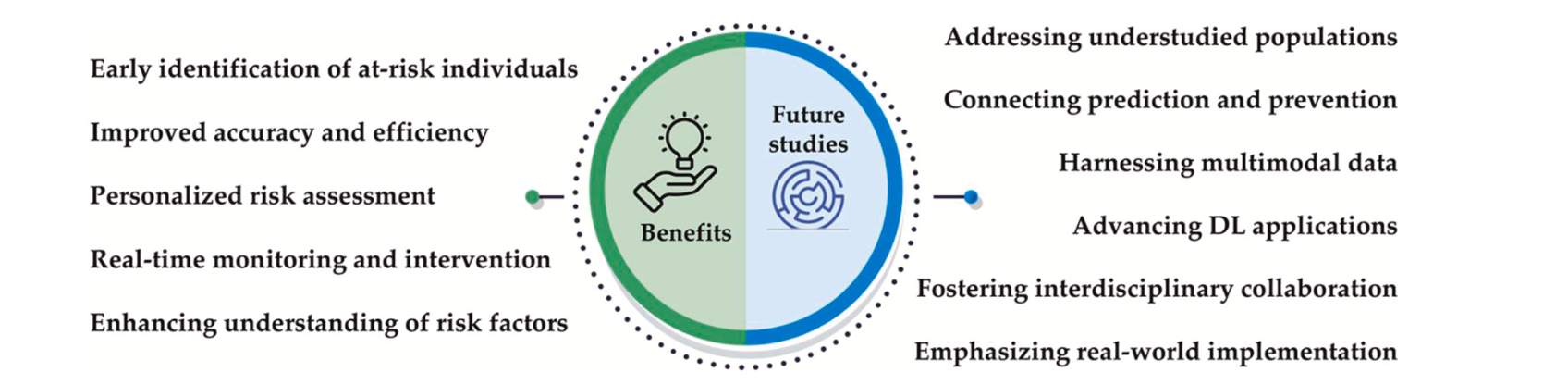
Suicide is a major global public health concern, and the application of artificial intelligence (AI) methods, such as natural language processing (NLP), machine learning (ML), and deep learning (DL), has shown promise in advancing suicide prediction and prevention efforts. Recent advancements in AI – particularly NLP and DL have opened up new avenues of research in suicide prediction and prevention. While several papers have reviewed specific detection techniques like NLP or DL, there has been no recent study that acts as a one-stop-shop, providing a comprehensive overview of all AI-based studies in this field. In this work, we conduct a systematic literature review to identify relevant studies published between 2019 and 2023, resulting in the inclusion of 156 studies. We provide a comprehensive overview of the current state of research conducted on AI-driven suicide prevention and prediction, focusing on different data types and AI techniques employed. We discuss the benefits and challenges of these approaches and propose future research directions to improve the practical application of AI in suicide research. AI is highly capable of improving the accuracy and efficiency of risk assessment, enabling personalized interventions, and enhancing our understanding of risk and protective factors. Multidisciplinary approaches combining diverse data sources and AI methods can help identify individuals at risk by analyzing social media content, patient histories, and data from mobile devices, enabling timely intervention. However, challenges related to data privacy, algorithmic bias, model interpretability, and real-world implementation must be addressed to realize the full potential of these technologies. Future research should focus on integrating prediction and prevention strategies, harnessing multimodal data, and expanding the scope to include diverse populations. Collaboration across disciplines and stakeholders is essential to ensure that AI-driven suicide prevention and prediction efforts are ethical, culturally sensitive, and person-centered. (Paper)
Deep learning in radiology for lung cancer diagnostics: A systematic review of classification, segmentation, and predictive modeling techniques
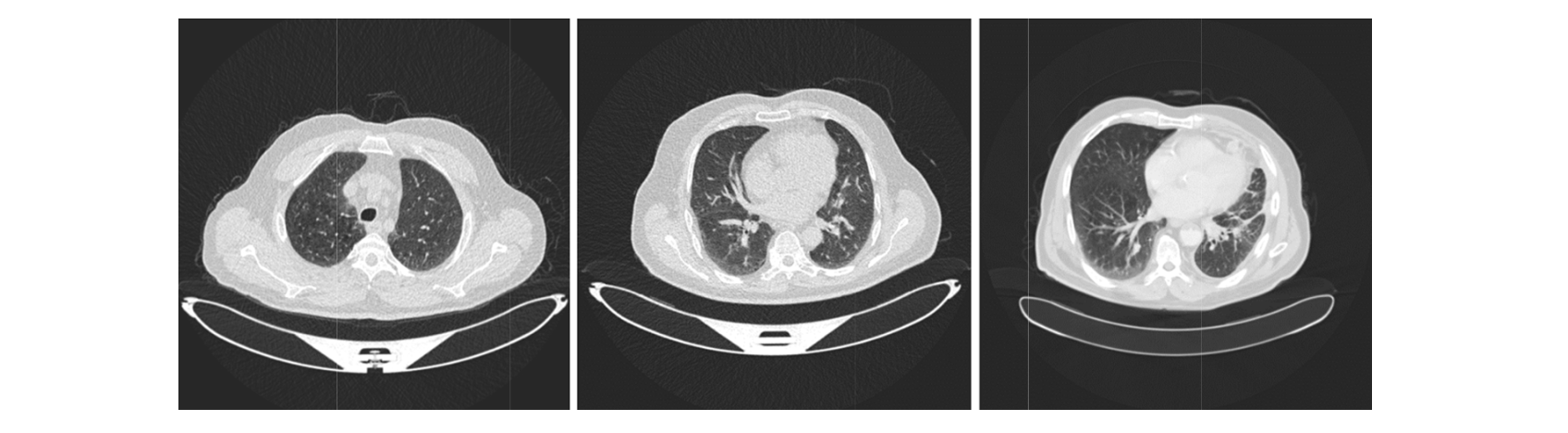
This study presents a comprehensive systematic review focusing on the applications of deep learning techniques in lung cancer radiomics. Through a rigorous screening process of 589 scientific publications following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, we selected 153 papers for an in-depth analysis. These papers were categorized based on imaging modality, deep learning model type, and practical applications in lung cancer, such as detection and survival prediction. We specifically emphasized deep learning models and examined their strengths and limitations for each application and imaging modality. Furthermore, we identified potential limitations within the field and proposed future research directions. This study serves as a pioneering resource, being the first comprehensive and systematic review of deep learning techniques, specifically in the context of lung cancer-related applications. Our primary objective was to provide a reference for future research, encouraging the advancement of deep learning techniques in the diagnosis and treatment of lung cancer. By suggesting the most effective deep learning tools for specific application areas, we offer a benchmark for future studies. In summary, this study consolidates and expands existing knowledge on deep learning and radiomics applications in lung cancer. It provides a foundation for further research and serves as a guide for developing and evaluating deep learning models in lung cancer-related applications. (Paper)
Artificial intelligence techniques for fibromyalgia: A systematic review of data-driven approaches and clinical implications (2013–2023)
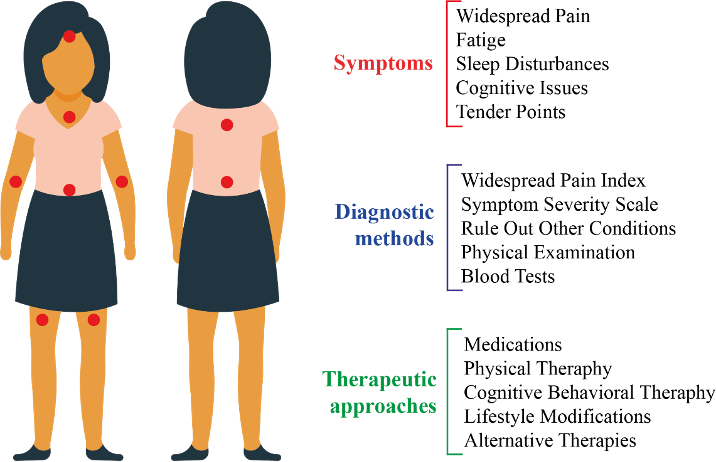
Fibromyalgia syndrome (FMS) is a long-lasting medical condition that poses significant challenges for diagnosis and management because of its complex and poorly understood nature. It affects millions of people around the globe, predominantly women, causing widespread pain, fatigue, cognitive impairments, and mood disturbances. The lack of objective measures to address FMS complicates its assessment, often leading to delayed or misdiagnosed cases. By hindering daily activities and productivity, FMS negatively impacts the quality of the patient’s life. Innovative approaches that use medical data, such as biosignals and bioimaging, combined with machine learning techniques, hold the promise of deepening our knowledge of FMS, which might in turn lead to systems that offer efficient, precise, and personalized physician support. Furthermore, artificial intelligence-driven identification of biomarkers and patient subgroups could improve FMS management. In this systematic review, we explore the role of artificial intelligence in understanding FMS pathophysiology, discuss the present limitations, and shed light on future research avenues, aiming to translate findings into improved clinical outcomes. (Paper)
Research Projects at BITS Pilani, India
Subject Line Generation using Artificial Intelligence and NLP
In this work, we built a transformer model to generate diverse email subject lines given a theme or starting word(s) as the input. For each input, we generated 10 semantically similar subject lines by considering it an English-English neural machine translation task. Finally, we built an LSTM model to predict open rates of emails that use the generated subject lines with a 91% accuracy. (GitHub)
Prediction of Video Game Development Problems using Word Embeddings
The interactive entertainment industry is being actively involved with the development, marketing, and sale of video games in the past decade. The increasing interest in video games has led to an increase in video game development techniques and methods. It has emerged as an immensely large sector, and now it has grown to be larger than the movie and music industries combined. The postmortem of a game outlines and analyzes the game’s history, team goals, what went right, and what went wrong with the game. Despite its significance, there is little understanding related to the challenges encountered by the programmers. Postmortems are not properly maintained and are informally written, leading to a lack of trustworthiness. In this study, we perform a systematic analysis of different problems faced in video game development. The need for automation and ML techniques arises because it could help game developers easily identify the exact problem from the description, and hence be able to easily find a solution. This work could also help developers in identifying frequent mistakes that could be avoided and will provide researchers a beginning point to further consider game development in the context of software engineering. (GitHub, Paper 1, Paper 2)
Adaptive Learning - Classification of Math Word Problems based on Difficulty Level
In this project, we built an ensemble learning classifier integrating features from word embeddings, parts of speech tags, and readability scores to predict the difficulty level of a given math word problem, achieving an AUC score of 0.92. (GitHub)
Emotionally Aware Conversational Agent for Mental Health
In this work, we built a multi-faceted emotionally aware chatbot combining rule-based, retrieval-based, and generative methodologies. We trained LSTMs and GRUs for the retrieval-based module and built a seq2seq encoder-decoder-based text generator for the generative module. (GitHub)
Mathematical Modelling of COVID-19
Mathematical predictions in combating epidemics are yet to reach their perfection. The rapid spread, the ways, and the procedures involved in the containment of a pandemic demand the earliest understanding in finding solutions in line with the habitual, physiological, biological, and environmental aspects of life with better computerized mathematical modeling and predictions. Epidemiology models are key tools in public health management programs despite having a high level of uncertainty in each one of these models. This paper describes the outcome and the challenges of SIR, SEIR, SEIRU, SIRD, SLIAR, ARIMA, SIDARTHE, etc., models used in prediction of the spread, peak, and reduction of COVID-19 cases. (Paper)